

摘要:当前Scaling Law面临瓶颈,基座大模型的未来发展需探索新方向。面对挑战,我们需要深入研究大模型的优化和扩展方法,提升模型性能。还需关注模型在实际应用中的表现,加强模型的可扩展性和通用性。基座大模型的发展将更加注重跨领域融合和智能化应用,以推动人工智能技术的持续进步。
本文目录导读:
随着人工智能技术的飞速发展,机器学习模型的大小和复杂性不断攀升,基座大模型(Foundation Models)已成为人工智能领域的重要支柱,随着Scaling Law(规模定律)可能遭遇瓶颈,我们如何找到基座大模型的未来方向?本文将就此展开讨论,并探索可能的解决方案和未来趋势。
Scaling Law的现状与挑战
Scaling Law描述了模型性能与模型规模之间的正相关关系,在人工智能发展的早期阶段,随着模型规模的扩大,性能得到了显著提升,当模型规模达到一定程度后,继续简单扩大规模可能不再带来显著的性能提升,甚至可能遭遇性能瓶颈,这一现象对于基座大模型的发展构成了重大挑战。
基座大模型的现状
基座大模型是人工智能领域的一种大型预训练模型,具有广泛的应用前景,这些模型通过在大规模数据集上进行训练,学习通用的知识表示,然后可以适应各种特定任务,目前,基座大模型在自然语言处理、计算机视觉等领域取得了显著成果。

面对挑战:寻找基座大模型的未来方向
1、任务适配性与连续性:未来的基座大模型需要更强大的任务适配性和连续性,这意味着模型不仅需要具备处理现有任务的能力,还需要具备适应未来新任务的能力,为此,研究人员需要设计更具灵活性和可调整性的模型结构,以便更好地适应不同任务的需求。
2、模型解释性与可信任性:随着模型规模的增大,模型的内部机制变得越来越复杂,导致模型的可解释性降低,为了提高模型的信任度,未来的基座大模型需要更加注重模型的解释性,研究人员需要探索新的方法,以便更好地理解模型的内部工作原理,从而提高模型的可信任度。
3、跨模态与多任务处理能力:现实世界中的许多问题涉及多种模态(如文本、图像、语音等)或多任务(如分类、回归、生成等),未来的基座大模型需要具备跨模态和多任务处理的能力,这要求模型能够融合不同模态的数据,并在多个任务上实现良好的性能。
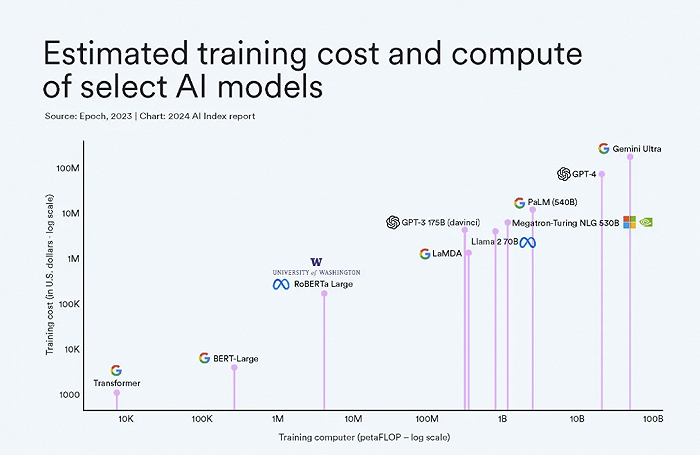
4、可持续性与绿色计算:随着模型规模的扩大,计算资源和能源消耗也在不断增加,为了降低环境成本,未来的基座大模型需要关注可持续性和绿色计算,研究人员需要探索更加高效的训练方法,以降低模型训练过程中的能耗和碳排放。
5、联邦学习与分布式训练:为了解决数据孤岛问题和保护用户隐私,联邦学习成为了一种重要的训练方式,未来的基座大模型可以借鉴联邦学习的思想,通过分布式训练来提高模型的性能,并降低对单一中心服务器的依赖。
6、结合领域知识与数据:为了进一步提高基座大模型的性能,我们可以结合领域知识和数据,通过引入领域专家的知识和数据,我们可以指导模型更好地学习相关任务,从而提高模型的性能。
7、持续研究与开放合作:人工智能领域的发展离不开持续的研究和开放合作,为了推动基座大模型的未来发展,我们需要保持对最新技术和趋势的关注,并加强学术界、工业界和政府部门之间的合作,共同推动人工智能领域的发展。
面对Scaling Law可能遭遇的瓶颈,基座大模型的未来发展需要我们从多个方面进行探索和努力,我们需要关注任务适配性与连续性、模型解释性与可信任性、跨模态与多任务处理能力、可持续性与绿色计算、联邦学习与分布式训练以及结合领域知识与数据等方面,通过持续的研究和开放合作,我们有信心找到基座大模型的未来方向,并推动人工智能领域的持续发展。
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号